Velocity Barcelone, premier jour
Baptiste, François et Olivier ont eu la chance de participer à la Vélocity Conférence Europe 2014 qui avait lieu cette année à Barcelone.
Voici le compte rendu des conférences et des moments qui les ont marqués.
Morning Keynotes
Les keynotes du matin semblaient être scénarisées sur différents points que les organisateurs de la conférence voulaient mettre en avant.
Life after human error - Steven Shorrock (EUROCONTROL)
Steven Shorrock n’est pas un homme de l’IT, mais travaille autour de la sécurité aérienne. Il se définit comme un ergonomiste des systèmes. Il a présenté comment, autour des erreurs humaines, “les mots créaient le monde” et entrainaient immédiatement un jugement social (“négligence” est évidement plus connoté que “erreur d’attention”). Il peut y avoir des erreurs dans la définition d’une erreur. Qualifier une erreur demandait une définition précise de standards et de contextes.
Il a également conseillé d’étudier les cas de fonctionnement normaux ; ne pas faire seulement des post-mortem mais des pre et des no mortem.
Une présentation intéressante sur l’incident et l’erreur.
Maximize the Return of Your Digital Investments - Aaron Rudger (Keynote Systems)
Une présentation sponsorisée bien faite, montrant les difficultés de communication entre deux populations (IT et biz en l’occurence) et comment un outil performant et agréable peut aider à combler ce gap.
Chez M6Web nous utilisons grafana, et il est vrai que cet outil pourrait largement sortir du périmètre de l’IT.
Slides : Maximize the Return of Your Digital Investments
Always Keep an Eye on Your Website Performance - PerfBar Khalid Lafi (WireFilter)
Une rapide démonstration d’un outil en javascript à installer sur les postes de vos développeurs et permettant d’afficher des alertes si un site en production (ou ailleurs) dépasse un certain seuil.
A découvrir : PerfBar
The Impatience Economy, Where Velocity Creates Value - Monica Pal (Aerospike Inc.)
Il y a une génération on attendait 10 jours un échange de courrier postal, aujourd’hui un adolescent vérifie son téléphone toutes les 10 secondes ! Nous sommes moins attentifs, plus impatients.
De ce constat Monica Pal explique comment les backend web doivent s’adapter et servir de plus en plus d’informations contextualisées : search, sort, recommand, personalize.
Slides : The Impatience Economy
Recruiting for Diversity in Tech - Laine Campbell (Pythian)
Un thème récurrent de la velocity de cette année. Laine explique comment l’ascenseur méritocratique est cassé et que seule une démarche volontaire permettra d’augmenter la diversité dans les entreprises.
Slides : Recruiting for Diversity in Tech
Better Performance Through Better Design - Mark Zeman (SpeedCurve)
La dernière keynote était vraiment excellente. Mark Zeman, venu de Nouvelle Zélande, a expliqué comment le processus créatif pouvait aider à améliorer la performance. Dans ce but il a proposé de redesign the design process.
- se fixer certains principes/objectifs de performance dès le départ
- ajouter les designers dans la feature team et itérer via des prototypes
- de partager le savoir sous forme d’informations visuelles (graphique mais aussi sous forme d’un bookmarklet indiquant quelle partie d’un site met du temps à charger)


Je vous invite vivement à regarder sa vidéo :
IT Janitor, How to Tidy Up - Mark Barnes (Financial Times)
Ce manager au Financial Times a expliqué comment le journal a été touché de plein fouet par la révolution du web mobile et a dû s’adapter très rapidement.
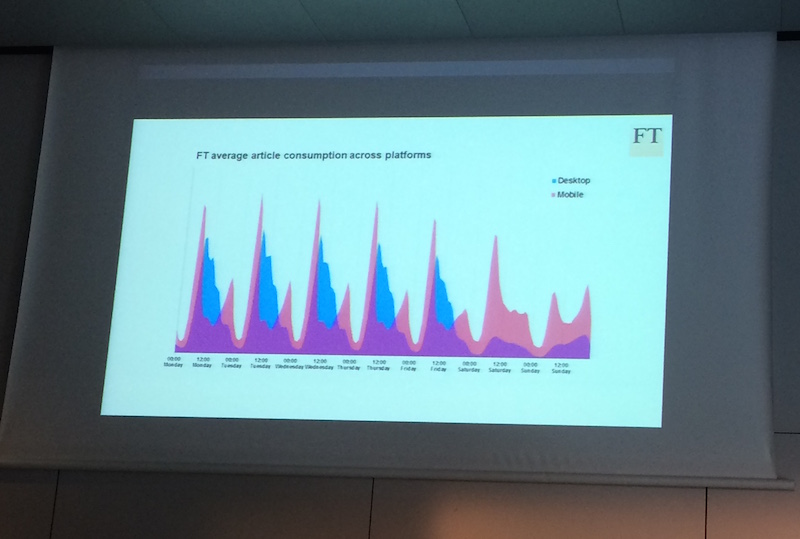
Il a expliqué quelle stratégie il a adoptée pour tuer ou refaire les vieux systèmes et comment, en premier lieu, il a vendu le projet à ses supérieurs.
Il a tout d’abord présenté le TCO de ce qu’il a appelé la version ”classic” de ft.com (la carotte) puis a appuyé sur la peur de l’incident et les problèmes de sécurité (le bâton ; le journal ayant été la cible des pirates syriens).
Après une analyse fine du traffic il a ensuite appliqué ces stratégies :
- tuer directement une application inutile (il y en avait), quitte à la rallumer si quelqu’un finalement en à l’usage :) (et couper un serveur Solaris avec 1833 jours d’uptime !)
- reécrire l’application et la redéployer sur le nouveau système
- tuer une application et écrire plusieurs autres (découpage en micro services)
Son crédo était ”try to make the right thing easier.” Ainsi les projets basés sur la nouvelle stack disposait out of the box de fonctionnalités de monitoring et de log. Cela a beaucoup motivé les équipes de développements.
Au final la purge du legacy a apporté :
- un gain de 30% de performance
- un meilleur TTM
- de substantiels retours sur investissement
Slides : IT Janitor - How to Tidy Up
Mansplaining 101: Cisadmin Edition - Marni Cohen (Puppet Labs)
La conférence la plus geek de la journée. La conférencière a ouvert un terminal et a tapé
brew install feminism

La conférence était très sincère et didactique sur comment mieux intégrer les femmes dans l’IT.
Voici les scripts et les ressources qu’elle a présentés : https://gitlab.com/marni/mansplaining
Building the FirefoxOS Homescreen - Kevin Grandon (Mozilla)
![]()
Slides : Building the FirefoxOS Homescreen
Conférence de présentation de l’OS pour smartphone de Firefox.
Lors de cette présentation, Kevin Grandon Ingénieur chez Mozilla nous a présenté le nouvel OS, et nous a initié à la programmation sur ce dernier. Ce nouvel OS est donc basé sur des langages simples : HTML / CSS / Javascript.
Le développement est donc assez facile à prendre en main, le débugage aussi car on peux monitorer tout ce qu’il se passe sur le device de test via un firebug dédié.
Don’t Kill Yourself : Mobile Web Performance Tricks that Aren’t Worth it, and Somme that Are - Lyza Gardner (Cloud Four)
Optimisations pour le web mobile.
Lyza Gardner nous a présenté sa vision de l’optimisation sur web mobile. Elle nous a tout d’abord fait un compte rendu sur son expérience personnelle. Liza a cherché via différentes analyses (speedIndex…) à trouver une relation entre temps de chargement, nombres d’assets etc… Et la conclusion qu’elle mettait en avant, c’est qu’il n’y avait pas de recette magique. Elle a ensuite fait la parallèle entre le web lors de ces débuts qui était limité par le débit de nos connexions de l’époque, et le web mobile tel qu’il est actuellement. Ainsi certaines optimisations de l’époque sont adaptables, et même toujours valables, à nos problématiques actuelles. Selon elle, il ne faut pas optimiser un site pour le mobile, mais l’optimiser tout court. Elle propose de se fixer des objectifs, par exemple se fixer une limite de nombre d’appel asset. Mais surtout d’optimiser / limiter les images puisque 62% du trafic d’un site correspond a ces dernières.
What are the Third-party Components Doing to Your Site’s Performance? - Andy Davies, Simon Hearne (NCC Group)
Slides : Third-party components and site performance?
Nous utilisons tous des « Third-Party » sur nos sites, mais est-ce une bonne idée ?
Un Third-Party est un script que nous chargeons depuis un autre site. Par exemple : Google Analitycs. Il existe différents type de Third-Party : la publicité, les analyseurs de trafic … La problématique est que nous ne pouvons pas controller ces outils. Nous n’avons pas la main sur le temps de chargement, la disponibilité de l’outils, et cela peut influer sur l’expérience utilisateur et la qualité de nos services.
Pour conclure, il faut trouver le bon compromis entre ce que nous apporte le Third-Party et ce qu’il peut nous coûter …
Guide to Survive a World Wide Event - Almudena Vivanco, Mateus Bartz (Telefónica
Slides : Survive a World Wide Event
Retour d’expérience de Movistar TV, une chaîne payante multi-support qui a diffusé la coupe du monde en Espagne, au Brésil et en Argentine.
Cette société s’est confrontée à une problématique de traffic avec des pics de connexions importants en peu de temps. La société devait diffuser la coupe du monde FIFA 2014 dans plusieurs pays et sur plusieurs devices différents. Après des tests en condition réelles avant le début de la compétition, ils se sont aperçus qu’ils ne pouvaient pas gérer le pic de connexion qui arrivait entre 5 minutes avant le coup d’envoi et 5 minutes après, ainsi qu’à la reprise du match et début de deuxième mi-temps.
Il a donc fallu tout refaire à plusieurs niveaux :
- Création d’un CDN en interne
- Refonte globale du système de connexion pour pouvoir supporter les pics.
- Mise en place de monitoring via Graphite
- Mise en place de Tests
Mise en avant de beaucoup de problématiques :
- Multi plateforme
- Déploiement sur plusieurs continents (Amérique du Sud, Europe)
- Rassembler 11 outils de monitoring en un seul.
Is TLS Fast yet ?
Slides : Is TLS Fast yet ?
TL;DR = Oui, il pourrait l’être !
Le talent d’Ilya pour les conférences techniques a une fois de plus fait ses preuves. Tout en détaillant l’utilité de TransportLayerSecurity (compression, vérification d’erreurs, authentification, chiffrement…) Ilya nous prouve que dans le meilleur des cas, un RTT supplémentaire est nécessaire et l’impact CPU très faible.
Outre l’utilisation des dernières versions du Kernel, d’OpenSSL et de votre OS serveur, la performance de TLS passe aussi par la réutilisation d’éléments négociés lors de la première (et coûteuse) poignée de main. Cette optimisation se fait coté serveur en conservant les “sessions identifiers” coté serveur ou coté client avec un “cookie” chiffré, le “session ticket”. Il faudra bien entendu ajuster la durée de cache et/ou les timeouts (~ 1 jour).
Une erreur fréquemment commise consiste à ne pas intégrer le certificat intermédiaire (peu de CA s’autorise à signer votre certificat avec leur CA Root) dans le certificat serveur ce qui a pour conséquence de stopper le render, ouvrir une nouvelle connexion tcp et https pour récupérer ce dernier chez l’autorité de certification.
L’OSCP stappling permet lui d’inclure directement la réponse OCSP et ainsi éviter le même problème de blocage du rendu, connexion à un tiers etc…
L’utilisation hasardeuse de redirection 301 peut considérablement augmenter le Time To First Byte de votre site, il est donc fortement conseillé de bien analyser ses chaînes de redirections (ex: https://domain.com => https://www.domain.com => https://www.domain.com) et d’utiliser HSTS. Ce header émis par le serveur permettra au navigateur de mettre en cache la décision de redirection vers https.
Le talk s’est terminé par un tableau comparatif fort intéressant des serveurs HTTP et des CDNs concernant tous ces aspects.
Quelques liens supplémentaires:
Monitoring: the math behind bad behavior
Slides : the math behind bad behavior
La détection d’anomalies dans les flux continus de données de type Time Series n’est pas une chose aisée.
Se baser sur un percentile, une moyenne ou une mediane uniquement ne permet pas de capturer les phénomènes de saisonnalité et d’anomalies.
Théo nous a proposé une méthode de détection de ces dernières appelée “lurching windows”. Sur des fenêtres de temps glissantes, on applique la méthode CUSUM (Cumulative Sum), qui somme les données en affectant un poids relatif (en réalité la probabilité que cette valeur existe).
A voir: https://en.wikipedia.org/wiki/CUSUM
What ops can learn from design - Robert Treat (OmniTI)
Slides : What ops can learn from design
“Un designer est quelqu’un qui design”.
Derrière cette lapalissade se cache en réalité plusieurs concepts importants à intégrer pour toutes personnes produisant un code, un service utilisé par un tiers.
Nous sommes tous des designers. Il est donc indispensable de mettre en oeuvre 3 mécanismes simples pour faciliter l’utilisation de votre code/service.
Le “Feedback”: le bon code de retour lors de l’échec d’un script, un message intelligible et contextualisé dans un log d’erreur applicatif, le “natural Mapping”: -d dans une option en ligne de commande pour indiquer –database, et le “force functions”: sous Unix, kill est par défaut non destructif, il faut forcer avec kill -9 pour tuer définitivement un processus, tout comme on vous force à fermer la porte de votre micro-onde pour le mettre en marche.
Conférence intéressante qui vous fera sentir moins coupable de ne pas savoir si il fallait pousser ou tirer une porte :)
Statistical Learning-based Automatic Anomaly Detection @Twitter
Arun Kejariwal est maintenant un habitué de la Velocity, j’avais particulièrement apprécié sa présentation l’année dernière à Londres sur la détection d’anomalies chez twitter.
L’ojectif est toujours le même: prédire la capacité pour ajouter du matériel en datacenter, détecter des événements particulier, distinguer le spam du trafic normal etc…
Leur méthode est relativement identique à ce qui avait été présenté l’année dernière: sur deux semaines de données on applique un traitement du signal pour décomposer et filtrer la saisonnalité. Il “suffit” ensuite d’appliquer une regression ou un ESD sur les résidus pour détecter d’éventuelles anomalies.
Chose à savoir: Twitter va publier un package R contenant ces fonctions et algorithmes, qui seront donc utilisables par le commun des mortels !
Conclusion
Une première journée intéressante et intense, sous le soleil de Barcelone !

Le résumé de la seconde journée est également disponible.